Anforderungen
Diese Anforderungsaufnahme beschreibt gesamthaft die Fähigkeiten, welche eine Datenfabrik Plattform-Architektur mitbringen muss, um zukünftigen, vielfältigen Nutzungsszenarien gerecht zu werden. Als Referenz für den Funktionsumfang wurden dabei existierende Use-Cases aus den Bereichen Haushalt & Finanzen sowie Schule herangezogen.
Zu beachten ist, dass die Anforderungen zum einen für die Plattform als Rahmen gelten (Querschnittsfunktionen), zum anderen aber auch für die Use-Cases, damit diese innerhalb der Plattform funktionieren. Querschnittsfunktionen sind explizit ausgewiesen, falls nicht spezifiziert gelten die Anforderungen für Use-Cases oder beide.

1. Funktionale Anforderungen
1.1 Authentifizierung & Authorisierung
Es ist jeder Anwendungsfall selbst für Authentifizierung sowie Authorisierung verantwortlich, falls der Anwendungsfall nicht öffentlich anonym nutzbar sein soll.
Die Authentifizierung ist dabei nicht innerhalb des Anwendungsfalles abzubilden (kein eigenes Nutzermanagement), sondern mittels Anbindung an einen OIDC-kompatiblen Identity-Provider (IDP) vorzusehen, aktuell kommen hier in Frage "["Keycloak SH" oder auch der IDP der Bildungsplattform.
Der jeweilige IDP sollte OIDC mit der Konfiguration Public Client / Standard flow anbieten.
- Hintergrund: um im Frontend (als sogenannte Single Page Application) einfache Skalierbarkeit zu ermöglichen, sollten die Container
statelesssein und auf eine Persistierung von Sessions verzichten. Sollte nur der Einsatz einesConfidential clientmöglich sein, würde dies bedingen, dass Sessions in einem Backend/BFF erzeugt und persistiert werden. Diese Sessions würden dann serverseitig gegenüber dem IDP validiert. - Implikationen: seitens IDP müssen Redirect URLs entsprechend eingeschränkt werden, um zu verhindern, dass der Token ausserhalb der Anwendung genutzt und damit missbraucht werden kann.
- beispielhafte Konfiguration von Keycloak: Aktivierung
Standard flow, DeaktivierungClient authentication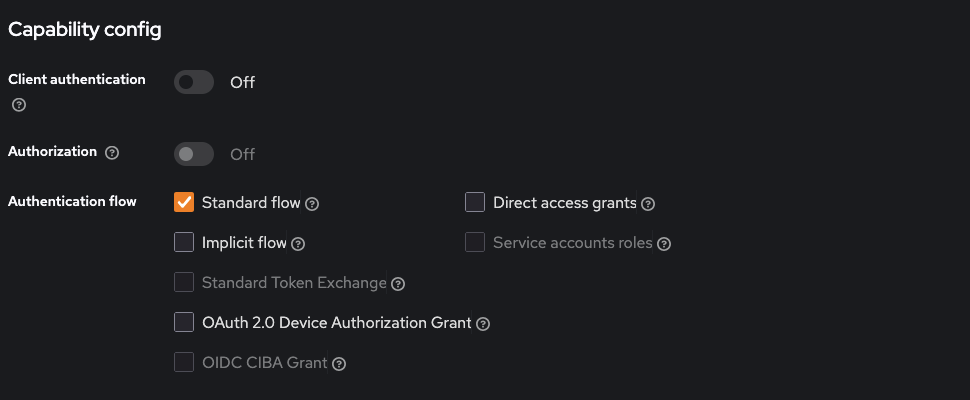
Authorisierung steuert, welche Ressourcen und Aktionen dem Nutzenden zur Verfügung stehen. Im Normalfall wird dies anhand der zugewiesenen Rollen ermittelt. Es erfolgt eine grundlegende Validierung der Berechtigung innerhalb eines Anwendungsfalles ebenso wie weitergreifende Berechtigungen (z.B. eine Rolle nur Lese-, eine andere auch Schreib-Rechte)
1.2 Data Apps
Unter "Data Apps" ist der Funktionsumfang gefasst, mit welchem (End)-Nutzer über eine visuelle Oberfläche mit Daten eines Use-Cases interagieren. Eine Data App kann dabei fachlich einem "Data Product" s.u. zugeordnet sein, aber auch mehrere solcher konsumieren. Nicht in einer Data App enthalten ist die gesamte Logik für Einlesen, Verarbeitung und Persistenz von Daten, wohl aber die nutzer-initiierte Übermittlung dieser an ein Data Product.
1.2.1 Generelle Frontend-Anforderungen
Für ein zeitgemäßes Nutzererlebnis sollte die genutzte Frontend-Technologie Single Page Applications (SPA) von Haus aus unterstützen.
Die Vorteile die sich daraus ergeben sind:
- erhöhte Responsivität bei Aktualisierung von dargestellten Inhalten
- größere Stabilität und Robustheit, bis hin zu Frontend-Cachen sowie Offline-Fähigkeit
- bessere Nutzererfahrung, da nur notwendige Teile des Frontends aktualisiert werden und dies schneller als bei traditionellen Webanwendungen
Modulares Design
Jedes Frontends sollte als eigenständige Einheit inkl. eigenen build/deploy- sowie Versionierungs-Zyklen gestaltet sein. Es ist dabei darauf zu achten dass keine Abhängigkeiten zwischen den Frontends anderer Use-Cases entstehen.
Sprachen und Frameworks
Primär sollten bewährte Sprachen eingesetzt werden, für welche eine entsprechende Verbreitung gegeben ist. Im Kontext von Frontend-Entwicklung ist dies zum einen HTML/CSS für die Darstellung, in den meisten Fällen wird dies aber durch JavaScript / TypeScript dynamisch erzeugt, augmentiert und orchestriert.
Innerhalb von JavaScript / TypeScript sind aktuell die Basis-Frameworks Vue/Nuxt, React/Next.js und Angular verbreitet. Da die Entwicklung hier schnell fortschreitet, gelten keine weiteren Einschränkungen an Basis-Frameworks, solange sie sich in einem weitgehend standardisierten CI/CD Prozess zu einem Container-Image kompilieren lassen.
Wichtig ist, dass Funktionen für das Management der Anwendungs-Views, Datenflüsse, State-Management sowie Backend-Interaktion schon innerhalb des Frameworks mitgebracht werden.
Frameworks, welche Backend-Technologien wie Python oder Java um eine Frontend-Ausgabe erweitern (Streamlit, Vaadin, Thymeleaf...) sollten nur nach Absprache und Bewertung von Alternativen zum Einsatz kommen, da hier meist ein Overhead entsteht.
State Management
Die Verwaltung des Anwendungsstatus ist in SPAs von entscheidender Bedeutung, insbesondere bei größeren Anwendungen.
Es sollte Mechanismen existieren, um den Anwendungsstatus während der Navigation und beim Neuladen zu erhalten.
Routing
Es sollte Client-seitiges Routing genutzt werden, um die Navigation innerhalb der Anwendung zu ermöglichen, ohne dass eine komplette Seite neu geladen werden muss. Bibliotheken wie React Router, Angular Router oder Vue Router können dies erleichtern.
Daten-Lade Strategien
Implementieren von effizienten Strategien zum Abrufen von Daten, wie z. B. Eager Loading, Lazy Loading oder Code-Splitting, um die Leistung zu optimieren.
Die Verwendung von GraphQL für das Abrufen von Daten ermöglicht es dem Frontend, genau die Daten anzufordern, die es benötigt, wodurch die bei REST-APIs häufig auftretenden Probleme des Über- und Unterabrufs reduziert werden.
Server Side Rendering & Caching
Die oben beschriebenen Vorteile einer SPA können im schlechtesten Fall zu negativen Effekten für die Ladezeit der ersten Seite und Einschränkungen in der Suchmaschinen-Optimierung mit sich bringen. Daher ist es essenziell, dass das eingesetzte Framework Features mitbringt, welche diese Gefahren mitigieren:
- Server Side Rendering: Seiten werden auf dem Server vorberechnet und als vollständiges HTML an die Clients ausgeliefert, zur Laufzeit werden dann die SPA Features hinzugefügt (Hydration)
- Caching: die vorberechneten Seiten sollten serverseitig zwischengespeichert werden, um zeitaufwändige Berechnungen nicht bei jedem Aufruf durchzuführen
1.2.2 Datenvisualisierung
Die meisten Use-Cases werden früher oder später Daten nicht nur tabellarisch, sondern auch visuell abbilden. Hier sollte vermieden werden, die Visualisierungen komplett selbst zu entwickeln. Stattdessen existieren diverse Frameworks, welche genutzt werden können. Nachfolgend finden sich Anforderungen an diese.
Umfangreiche Charting-Optionen
Gebräuchliche Typen welche unterstützt werden sollten sind Bar Charts, Line Graphs, Pie Charts, Scatter Plots, Heatmaps aber je nach Use-Case auch komplexere Arten wie Sankey Diagramme oder Baum-Diagramme.
Interaktivität und Responsivität
Interaktive Visualisierungen ermöglichen es Nutzern Daten genauer zu untersuchen. Funktionen wie Tooltip, Zoom oder Filter können das Nutzererlebnis bedeutend verbessern und zum Verständnis der Daten beitragen.
Die Visualisierungen sollten sich responsiv an unterschiedliche Bildschirmauflösungen und Geräte anpassen. Dies ist essenziell für ein konsistentes Nutzererlebnis auf Desktop- und Mobilgeräten.
Barrierefreie Diagramme
Es sollte sichergestellt werden, dass Visualisierungen für alle Nutzer, inkl. derer mit Beeinträchtigungen, zugänglich sind. Semantisches Markup kann alternative Text-Beschreibungen für Abbildungen liefern.
Siehe auch unten für generelle Hinweise zur Barrierefreiheit.
Performance
Das Rendering von Visualisierungen sollte optimiert stattfinden, um Leistungsengpässe zu vermeiden, insbesondere bei großen Datensätzen.
Server Side Rendering
Soweit möglich sollten Diagramme auch serverseitig vorberechnet werden können.
Dokumentation und Community-Support
Es sollte bei der Auswahl des Visualisierungsframeworks auf eine ausführliche Dokumentation und eine aktive Community geachtet werden. Beides erleichtert die Fehlerbehebung und den laufenden Betrieb.
1.2.3 Barrierefreiheit
Der innerhalb der Anwendungsfälle zu erreichende Grad der Barrierefreiheit muss mindestens die Konformitätsstufe AA gemäß WCAG 2.1 erfüllen, da sich die primären Nutzungsszenarien in der öffentlichen Verwaltung abspielen.
Hintergrund-Informationen (Quelle):
-
Barrierefreie Informationstechnik-Verordnung (BITV 2.0): Die BITV 2.0 soll eine umfassend und grundsätzlich uneingeschränkt barrierefreie Gestaltung moderner Informations- und Kommunikationstechnik ermöglichen und gewährleisten. Sie präzisiert die Anwendung des BGG für den Bereich der IT der öffentlichen Stellen des Bundes und definiert u.a. im § 3 auch die anzuwendenden Standards für Barrierefreiheit.
-
Harmonisierte Europäische Norm (EN 301 549): Laut BITV wird die Erfüllung der Anforderungen an Barrierefreiheit vermutet, wenn diese der harmonisierten EU-Norm entsprechen. Die EN 301 549 ist damit die wichtigste Sammlung von einschlägigen Barrierefreiheitsanforderungen an die Informationstechnik (Web, Software, Hardware, mobile Anwendungen und Dokumente) der öffentlichen Stellen des Bundes.
-
Web Content Accessibility Guidelines (WCAG 2.1): WCAG ist ein internationaler Standard des World Wide Web Consortiums (W3C) zur barrierefreien Gestaltung von Internetangeboten. Eine Vielzahl der Anforderungen der EN 301 549 verweist auf die sehr gut dokumentierten WCAG-Kriterien, nämlich auf die Anforderungen der Konformitätsstufen A und AA. Wenn das höchstmögliche Maß an Barrierefreiheit gemäß § 3 Absatz 4 BITV für Websites und Webanwendungen anzustreben ist, sollen die Anforderungen der Konformitätsstufe AAA erfüllt werden.
1.2.4 Design-System / Komponenten-Bibliothek
Es gibt keine starre Vorgabe, welche Design-System oder Komponenten bei der Entwicklung der Frontend-Anwendungen einzusetzen sind.
Da allerdings mit Kern (v2) aktuell ein UX-Standard für die deutsche Verwaltung geschaffen wird, sollte vor dem Einsatz anderer Optionen der aktuelle Entwicklungsstand (vgl. Roadmap von Kern (v2)) geprüft und wenn möglich genutzt werden. Gerade wenn seitens Kern (v2) schon Theming-Optionen für das Bundesland und/oder Komponenten für die fachliche Ausgestaltung existieren, sind hierbei Synergie-Effekte zu erwarten.
Weiterführende Links:
- https://www.kern-ux.de/ueber-kern/roadmap/
- https://www.kern-ux.de/design-system/foundations/design-token
- https://www.kern-ux.de/design-system/foundations/farbe/
Im Rahmen der übergreifenden Gestaltung ist darüber hinaus die Anwendbarkeit der Digitalen Dachmarke zu prüfen, vgl. https://www.digitale-verwaltung.de/Webs/DV/DE/aktuelles-service/digitale_dachmarke/digitale_dachmarke-node.html. Die digitale Dachmarke besteht aus vier Kennzeichnungselementen, die modular und freiwillig eingesetzt werden können: Kopfzeile, Domain-Name, Bildzeichen und Designsystem.
Die Plattform selbst stellt kein Design-System oder Komponenten zur Verfügung.
1.2.5 Backend for Frontend
Ein Backend for Frontend (BFF) sollte APIs bereitstellen, die speziell auf die Anforderungen der Frontend-Anwendung zugeschnitten sind. Dies kann die Aggregation von Daten aus verschiedenen Quellen, die Umwandlung von Datenformaten oder die Implementierung von Geschäftslogik umfassen, die nur für das Frontend relevant ist. Somit kann das Data Product Daten unabhängig von spezifischen Darstellungswünschen eines Frontends ausliefern.
Zu den Best-Practice-Empfehlungen für ein BFF gehören:
- Verwenden desselben Technologie-Stack wie das Frontend, um die Entwicklung und das Debugging zu vereinfachen.
- Umsetzung so schlank wie möglich, Konzentration auf Frontend spezifische Belange.
- Zustandslos - es sollten keine Sessions gehalten werden, um Skalierung in der Infrastruktur nicht zu behindern
- Regelmäßige Überprüfung und Refaktorierung des BFF, um veränderte Frontend Anforderungen und Best Practices zu berücksichtigen.
Separation of Concerns
Der Hauptzweck des BFF besteht darin, die Frontend- und Backend-Teams zu entkoppeln und eine unabhängige Entwicklung, Bereitstellung und Skalierung zu ermöglichen.
Performance Optimierung
Wenn möglich die Datenübertragung zwischen dem Frontend und dem Backend optimieren, indem es die Größe der Nutzdaten reduziert, Caching-Strategien implementiert oder Techniken wie die Datendeduplizierung einsetzt.
Sicherheit
Durchsetzung spezifischer Sicherheitsrichtlinien für das Frontend, z. B. Ratenbegrenzung, Eingabevalidierung oder Token-Authentifizierung um so die Backend-Anwendungen vor direktem Zugriff zu schützen.
Realtime Fähigkeiten
Technologien wie WebSockets oder Server-Sent Events können zwischen BFF und Frontend genutzt werden, um Echtzeitfunktionen wie Live-Updates oder Benachrichtigungen darzustellen.
Logging und Monitoring
Dedizierte Protokollierung und Überwachung für das BFF können Einblicke in Frontend Nutzungsmuster, Leistungsmetriken und potenzielle Probleme geben.
1.3 Data Products
Ein "Data Product" beschreibt aus Sicht der Datenfabrik Plattform den domänenspezifischen Teil einer Anwendung, um Daten zu empfangen, zu transformieren, zu persistieren und zur Nutzung durch eine oder mehrere "Data App(s)" oder auch andere API-Konsumenten zur Verfügung zu stellen. Nicht enthalten ist ein Frontend mit welchem End-Nutzer interagieren können. Auch können Daten strukturell abweichend von den Anforderungen eines Frontends ausgeliefert werden, die Verantwortung für eine notwendige Transformation für das Frontend liegt im Backend for Frontend.
1.3.1 API Management - Querschnittsfunktion
Der Einsatz einer API Management / Gateway Komponente bietet Vorteile für die Plattform, was Sicherheit, Performance und Developer-Experience angeht. API Management ist die zentrale Stelle für Design, Deployment, Absicherung, Monitoring und Skalierung von APIs, erleichtert die Management-Prozesse und ermöglicht Konsistenz über den API Lifecycle.
Folgende Anforderungen sollten durch eine solche Komponente erfüllt werden.
Sicherheit und Zugriffsschutz
Robuste Sicherheitsfeatures sollten zur Verfügung stehen, z.B.:
- Authentifizierung und Authorisierung, OAuth/OpenID Connect
- Rate-Limiting / Throttling / DDoS Schutz
- API Key Management
- API Gateway/Firewall-Funktionen gegen SQL-Injektion oder DDoS Attacken
Versionierung und Lifecycle Management
Versionierung ermöglicht es, Änderungen an bestehenden APIs zu verwalten und neue Versionen einzuführen, ohne bestehende Integrationen durch Data Apps oder externe API Konsumenten zu unterbrechen.
Traffic Management
Kernfunktionen sind Routing, Priorisierung und Transformation von API-Anfragen. Darüber hinaus aber auch Load-Balancing, Canary Releases, A/B-Tests und Blue-Green-Implementierungen. Außerdem sollte die Komponente Caching- und Komprimierungsfunktionen bieten, um die Leistung zu verbessern und Latenzzeiten zu reduzieren.
Skalierbarkeit und High Availability
Der API Gateway sollte so entwickelt sein, dass er hohe Last verarbeiten und im Bedarfsfall horizontal skalieren kann, um optimale Performance und Zuverlässigkeit zu gewährleisten.
Analytics und Monitoring
Umfassende Analyse- und Überwachungsfunktionen, die Einblicke in die API-Nutzung, Leistung und potenzielle Probleme bieten. Dies ermöglicht eine datengesteuerte Entscheidungsfindung und proaktive Problemlösung.
Compliance und Governance
Unterstützung der Einhaltung von Branchenvorschriften und internen Richtlinien durch die Durchsetzung von Sicherheitsprotokollen, Datenverschlüsselung und Prüfungsfunktionen.
1.3.2 Data Access API
Das Data Product sollte Daten über gut-dokumentierte, performante Schnittstellen (APIs) zur Verfügung stellen. Abhängig vom Use-Case können hierfür REST, GraphQL oder gRPC Schnittstellen zum Einsatz kommen.
Die übergreifenden Anforderungen an eine solche API finden sich nachfolgend.
Sprachen / Frameworks
Es gilt wie oben - primär sollten bewährte Sprachen eingesetzt werden, für welche eine entsprechende Verbreitung und aktives Ökosystem gegeben ist. Um Entwicklungsaufwände gering zu halten, empfiehlt sich ein "Batteries included" Ansatz bei der Auswahl, d.h. möglichst viele Funktionen sollten als existierende Module oder direkt im Framework verfügbar sein.
Beispiele für gängige Sprachen und Frameworks sind:
- Python mit FastAPI (oder auch Flask)
- Java mit Springboot (oder auch Quarkus)
- NodeJS mit NestJS (oder auch TSOA)
Authentifizierung/Authorisierung
Im Gesamtbild finden auch schon vor der Data Access API Prüfungen auf Zugriffsberechtigung statt, nichtsdestotrotz muss die API aber auch diese Funktionen mitbringen, da mindestens ein Token (z.B. JWT) beim Aufruf validiert werden können muss, meist aber auch weiterreichende Aufrufe an Schnittstellen für Nutzer-Infos notwendig sein werden. Hier muss mindestens OIDC unterstützt werden.
API-Konnektoren
Die Schnittstelle der Data Access API wird nach aktuellem Stand so gut wie immer eine JSON basierte REST API sein, d.h. eingehende Anfragen via HTTP Protokoll werden durch die API beantwortet.
Zukünftig sind aber auch weiterreichende Integrationen denkbar, sodass z.B. ein Auslöser auch eine Nachricht in einer Queue/Warteschlange sein kann, welche dann entsprechende Prozesse in der API anstösst.
In einem solchen Fall sollte das verwendete Framework weitere Konnektoren so einfach wie möglich nutzen können, zum Beispiel:
- gRPC
- Redis
- MQTT
- AMQP
- Kafka
ORM-Support
Wenn möglich sollte ein Framework eingesetzt werden, welches ORM (Object Relational Mapping) unterstützt, da dies etliche Vorteile mitbringt:
- Vereinfachte Datenbankinteraktion: Abstrahierung von SQL und direkter Datenbankinteraktion, Interaktion mit Datenbanken durch objektorientierte Konzepte. Dies führt zu saubererem, besser lesbarem und wartbarem Code.
- Produktivitätssteigerung: Automatisierung von Aufgaben wie die Erstellung von SQL-Abfragen, die Abwicklung von Transaktionen, die Verwaltung von Verbindungen und die Übersetzung zwischen Objekten und Datenbanktabellen. Dies kann die Produktivität der Entwickler erheblich steigern und die Fehlerwahrscheinlichkeit verringern.
- Datenbank-Agnostisch: Unterstützung mehrerer Datenbankanbieter (z. B. MySQL, PostgreSQL, SQLite usw.), sodass mit minimalen Codeänderungen Datenbanksysteme gewechselt werden können. Dies fördert die Flexibilität und vermeidet die Bindung an einen bestimmten Anbieter.
- Datenvalidierung und Geschäftslogik: ORMs ermöglichen die Kapselung von Datenvalidierungsregeln und Geschäftslogik direkt innerhalb der Domänenobjekte. Diese Trennung von Belangen führt zu saubererem, besser wartbarem Code und reduziert Duplikation.
- Schema-Veränderungen: Einige ORMs unterstützen die automatische Migration des Datenbankschemas auf der Grundlage von Änderungen an den Domänenobjekten. Dies vereinfacht den Prozess der Anpassung des Datenbankschemas an sich entwickelnde Anwendungsanforderungen.
- Caching und Performance-Optimierung: Viele ORMs bieten integrierte Unterstützung für Caching, Abfrageoptimierung und Verbindungspooling, was die Anwendungsleistung verbessern und die Datenbanklast reduzieren kann.
Dokumentation der APIs
Es ist essenziell, dass die Dokumentation mit der Codebasis synchron bleibt, um jegliche Anbindung/Nutzung so gut wie möglich zu befähigen. Dafür sollte die Dokumentationserstellung automatisiert geschehen.
Technisch müssen alle Endpunkte im Swagger/OpenAPI Spezifikations-Format (OAS 3.0) beschrieben werden. Normalerweise bieten sich dafür entsprechende Annotationen im Code selbst an.
Für die APIs (zumindest in non-produktiven Umgebungen) muss eine entsprechende automatisch auf Grundlage der Spezifikation generierte UI zur Interaktion zur Verfügung stehen.
Fachliche und weiterführende Dokumentationen können in den Quellcode-Repositories in Form von Markdown/Adoc Dokumenten abgelegt werden, bei Bedarf/Möglichkeit können auch diese aus Code erzeugt werden (wie z.B. helm-docs für Dokumentation von Helm-Charts.)
Kubernetes-Fähigkeit
Die Betriebsumgebung (s.u.) wird im Normalfall eine Kubernetes-Umgebung sein. Die APIs sollten daher unter Berücksichtigung von Kubernetes konzipiert und implementiert werden da dies die Bereitstellung, Verwaltung und Skalierung innerhalb von Kubernetes und seinem Ökosystem erleichtert. Im besten Fall bringen die genutzten Frameworks entsprechende Funktionen schon mit.
- Stateless Design: eine Instanz der API sollte von Request zu Request keinerlei client-spezifischen Zustände halten, da nur so einfach horizontal skaliert werden kann
- Environment Variablen und Secrets: Nutzung für Konfigurations- und sensible Daten, um die Abgrenzung der Zuständigkeiten zu gewährleisten und die Bereitstellung über verschiedene Umgebungen hinweg zu vereinfachen.
- Liveness und Readiness Probes: Kubernetes unterstützt Zustandsprüfungen durch Liveness- und Readiness-Probes. Eine Kubernetes-fähige API sollte entsprechende Health-Check Endpunkte implementieren, um Kubernetes den Gesundheitszustand zu signalisieren und so intelligente Skalierung und Selbstheilungsfunktionen zu ermöglichen.
- Observability und Monitoring: Kubernetes lässt sich mit verschiedenen Überwachungs- und Protokollierungstools integrieren. Eine Kubernetes-fähige API sollte aussagekräftige Metriken und Protokolle ausgeben, die die Überwachung und Beobachtbarkeit mit Tools wie Prometheus, Grafana, ELK Stack oder Jaeger erleichtern.
1.3.3 Data Ingest (Extract/Load/Transform) - Querschnittsfunktion
Der Fokus des Daten Ingest in der Plattform liegt darauf, wiederkehrende Use-Case spezifische Entwicklung von Verarbeitungslogik zu vermeiden und stattdessen mittels einer konfigurierbaren Laufzeitumgebung diese so weit wie möglich deklarativ vorzunehmen.
Die folgenden Anforderungen beschreiben die Grundlagen für eine Ingest-Funktionalität, welche Robustheit, Wartungsfähigkeit sowie Skalierbarkeit unterstützt.
Konnektivität zu Datenquellen:
- Unterstützung einer breiten Palette von Datenquellen, einschließlich Datenbanken (relational und NoSQL), Flat Files (CSV, JSON, XML), Cloud-Speicher (S3) und Streaming-Plattformen (Kafka, Kinesis).
Datenextraktion
- zuverlässige Extraktionsmechanismen für jede unterstützte Datenquelle.
- Behandlung von Teilausfällen, um die Datenkonsistenz und -integrität zu gewährleisten.
- Optionen für eine vollständige oder inkrementelle Extraktion auf der Grundlage der Anforderungen an die Datenaktualität.
Datenumwandlung
- flexibles und erweiterbares Transformations-Framework, mit dem Benutzer benutzerdefinierte Transformationen über eine einfache und intuitive Syntax oder eine visuelle Schnittstelle definieren können.
- Unterstützung gängiger Datenverarbeitungsoperationen (Filter, Aggregate, Join, Fensterfunktionen usw.) und benutzerdefinierter Funktionen (UDFs).
- Sicherstellung, dass Transformationen idempotent sind und eine erneute Verarbeitung von Daten ohne Nebeneffekte ermöglichen.
- Speicherung von Metadaten über Datenquellen, Schemata, Transformationen und Abstammung.
Datenüberprüfung
- robuste Datenvalidierungsprüfungen, um die Integrität und Konsistenz der Daten zu gewährleisten.
- Validierung von Daten anhand vordefinierter Schemata.
Serialisierung und Deserialisierung von Daten
- Unterstützung verschiedener Datenformate für die Eingabe und Ausgabe, wie JSON, Avro, Parquet oder CSV.
- Optimierte Serialisierung und Deserialisierung im Hinblick auf Leistung und Speichereffizienz.
Erweiterbarkeit und Anpassbarkeit
- Erweiterung und Anpassung von Verarbeitungsprozessen durch Einfügen benutzerdefinierter Module oder Skripte.
- Unterstützung benutzerdefinierter Funktionen (UDFs) und benutzerdefinierter Aggregationsfunktionen (UDAFs) für erweiterte Transformationen.
- im Kontext "Plattform" ist hier vor allem auch wichtig, in welcher Form ein Use-Case eigene Prozesse definieren und bereitstellen kann
Überwachung der Datenqualität
- Implementierung von Datenqualitätsprüfungen und Metriken zur Überwachung der Aktualität, Vollständigkeit und Konsistenz der Daten.
- Benachrichtigung der Beteiligten bei Datenqualitätsproblemen und Bereitstellung von Mechanismen zur Abhilfe.
Gleichzeitigkeit und Parallelverarbeitung
- Nutzung von Multi-Threading, asynchroner Verarbeitung oder verteilter Datenverarbeitung, um die Leistung zu verbessern.
- Gewährleistung von Thread-Sicherheit und Ressourcenmanagement in parallelen Umgebungen.
Fehlertoleranz und Wiederholungsmechanismen
- Implementierung von fehlertoleranten Designprinzipien, um vorübergehende Ausfälle zu mitigieren und die Datenkonsistenz zu gewährleisten.
- Bereitstellung konfigurierbarer Wiederholungsmechanismen mit exponentiellem Backoff und Jitter für fehlgeschlagene Operationen.
Skalierbarkeit und Leistung
- die Anwendung sollte horizontal skalierbar sein
- Optimieren der Leistung durch Techniken wie Datenpartitionierung, Komprimierung und effiziente Datenspeicherung.
- Unterstützung von internen/externen Warteschlangen (Queues)
Monitoring und Logging
- Integration mit Überwachungs- und Protokollierungstools zur Verfolgung der Verarbeitungsleistung, Ressourcennutzung und Fehlerquoten.
- Bereitstellung von Alarmierungsmechanismen für Ausfälle, Leistungsverschlechterungen oder Datenqualitätsprobleme.
Versionierung und Rückwärtskompatibilität
- Versionierung für Datenquellen, Schemata und Transformationen, um die Abwärtskompatibilität zu gewährleisten.
- bei Bedarf Mechanismen zum Zurücksetzen auf frühere Versionen.
Betrieb in gemeinsamer Kubernetes Umgebung
Die Komponente sollte möglichst querschnittlich allen Use-Cases zur Verfügung gestellt werden. Dies bedingt:
- Deployment der Anwendung unabhängig von Prozessierungs-Pipelines/-Flows
- Deployment von Pipelines/Flows muss in laufende Anwendung möglich sein
- die Anwendung muss eine Mandanten-Trennung unterstützen, sodass ein Use-Case nicht auf Daten eines anderen Use-Case zugreifen kann
1.3.4 Persistenz - Querschnittsfunktion
Für eine Speicherung der Daten muss seitens der Plattform sowohl die Möglichkeit bestehen, diese in relationalen- (für strukturierte), nicht-relationalen- (für semi/nicht-strukturierte) als auch Zeitreihen-Datenbanken abzulegen. Darüber hinaus muss die Möglichkeit gegeben sein, Dateien/Objekte unabhängig von einer Datenbank in einem dateibasierten Speicherdienst abzulegen.
Für alle Arten der Speicherung muss die Beständigkeit und Verfügbarkeit durch Mechanismen wie Backups und Replikation sichergestellt werden.
Relationale Datenbanken
In der aktuellen Anforderungslage sind Daten vorrangig relational, daher liegt der Fokus auf der Betrachtung von dafür geeigneten Datenbanken.
Dateien und Objekte
Präferiert ist, Daten welche keine temporären Arbeitsstände sind, in einem S3 Object-Storage abzulegen. Dies ermöglicht eine automatische Versionierung, hohe Verfügbarkeit sowie Datenhaltung abseits der Laufzeit-Umgebung des Data Products.
2. Betriebliche Anforderungen - Querschnittsfunktion
2.1 Betriebliche Artefakte
Betriebliche Artefakte sind die konkreten Ergebnisse der Implementierung, die verpackt und in verschiedenen Umgebungen (z.B. Entwicklung, Staging, Produktion) bereitgestellt werden müssen, um einen konsistenten und zuverlässigen Betrieb zu gewährleisten. Beispielhaft sind dies:
- Container Images: OCI konforme container images für die Plattform inkl. der Querschnittsfunktionen sowie Use-Case spezifische container images für Data Apps & Data Products
- Kubernetes Manifeste und Helm Charts: Kubernetes Manifeste definieren den gewünschten Zustand der Anwendungen, zum Beispiel für Deployments, Services, ConfigMaps, Secrets und PersistentVolumeClaims. Für die Bereitstellung auf unterschiedlichen Umgebungen sollten allerdings Helm Charts eingesetzt werden, um Konfigurationswerte von den Manifesten zu entkoppeln und das Deployment zu vereinfachen.
- CI/CD Pipelines: Continuous Integration/Continuous Deployment (CI/CD)-Pipelines automatisieren die Build-, Test- und Bereitstellungsprozesse. Zu den Artefakten im Zusammenhang mit CI/CD-Pipelines gehören Pipeline-Konfigurationsdateien (z. B. Jenkinsfile, GitLab CI YAML oder GitHub Actions Workflow-Dateien) und während des CI-Prozesses generierte Build-Artefakte.
2.2 Umgebungen und Deploymentwege
Grundsätzlich werden alle Umgebungen auf Kubernetes basieren. Je nach Schutzbedarf und Kontext sind folgende Ausprägungen denkbar. Annahme ist dabei, dass die Plattform mehrfach instanziiert werden kann.
Offen (auf open-code)
Eine Instanz der Plattform läuft öffentlich erreichbar. Use-Cases können via Self-Service Deployment ohne formale Prozesse bereitgestellt und in der Plattform registriert werden. Dies ist nicht möglich, falls die Anwendungen den Schutzbedarf "Hoch" haben.
Es sollte möglich sein, eine Anwendung per Auto-Deploy rein basierend auf dem Anwendungscode bereitzustellen
Das verantwortliche CI/CD liegt dabei im Open-Code Gitlab. Container Images in der Open-Code Gitlab Container Registry.
Abgesicherte Umgebung
Für Anwendungen mit Schutzbedarf "Hoch" läuft eine Instanz der Plattform in einem Rechenzentrum von DataPort. Sowohl die Plattform als auch die Use-Cases dürfen nur im Rahmen von Change/eHdB-Prozessen produktiv bereitgestellt werden.
Anwendungen welche in einer offenen Instanz bereitgestellt wurden, müssen über geeignete Mechanismen auch in der abgesicherten Umgebung verfügbar gemacht werden können.
Das verantwortliche CI/CD liegt dabei im DataPort Gitlab. Container Images im DataPort Artifactory.
2.3 Monitoring
Die Plattform inkl. der Use-Cases besteht aus mehreren Software-Komponenten, über welche die Funktionalität verteilt ist. Als solche ist es essenziell, aussagekräftige Funktionen für die Untersuchung des Verhaltens und die Fehleranalyse zu bieten.
System Health Monitoring: sollte vom Betreiber der Infrastruktur erbracht werden, dazu gehören - CPU, Speicher- und Storage-Nutzung - Netzwerk Durchsatz und Latenz - Storage Kapazität
Container und Cluster Monitoring: sollte vom Betreiber der Kubernetes-Cluster erbracht werden, dazu gehören: - Pod und Node Status - Ressourcen Zuweisung und Nutzung - Container image Gesundheit und Vulnerability Scanning - Kubernetes Cluster Gesundheit
Log Aggregation and Analysis: sollte im Rahmen eines Infrastruktur-Dienstes unterhalb der Plattform erbracht werden, dazu gehören: - Zentralisiertes Log-Management und -aggregation - Log-Parsing - Log-basierte Warnmeldungen und Erkennung von Anomalien
2.4 Benachrichtigungen und Mailversand
In der ersten Ausprägung der Plattform sind keine mobilen Push-Benachrichtigungen notwendig, es muss allerdings möglich sein aus den Use-Cases heraus auf einem standardisierten Weg E-Mails an Nutzer der Plattform zu versenden. Dies beinhaltet weder den Massenversand von E-Mails (z.B. Newsletter) noch ist eine Fokussierung der Use-Cases auf Nachrichtenversand mit höherem Volumen absehbar.
3. Sonstige und übergreifende Anforderungen
3.1 Einsatz von Open-Source
Die Plattform inkl. der Querschnittsfunktionen muss auf Open-Source Komponenten basieren und ihrerseits auch offen und uneingeschränkt einsetzbar sein. Einer Nachnutzung durch Dritte dürfen somit keine Lizenz-Schwierigkeiten im Wege stehen, es muss möglich sein, den veröffentlichten Code der Plattform selbständig in Betrieb zu nehmen.
Falls proprietäre Komponenten zum Einsatz kommen, muss es für diese eine funktional gleichwerte Open-Source Entsprechung geben und etwaige Adapter/Client-Implementierungen müssen beide Ausprägungen nutzen können.
Details siehe Open Source